
미완
기초 SQL 학습 3일차
❇️ 오늘 배운 내용
1.
2.
3.
주요 개념
| JOIN | INNER JOIN ... ON |
오전 강의
| 소제목
요약
- 그룹 바이

where에서 별명을 사용할 수 없는 것과 같은 맥락이에요~
순서를 잘 익혀두세요 나중에 헷갈리니까요.
파잉썬은 내가 쓴 순서대로 실행이 되니까 (메서드 체이) 논리가 헷갈릴 수 있는데
sql은

그룹 바이 - 엑셀의 피벗 테이블 같은 것
정해진 문법 순서, 순서와는 다르게 미리 정해진 내부 처리 순서
에 따라 쓴다
파이썬은
정해지지 않은 순서고 쓰는 순서에 따라 처리되는 거라서 논리 꼬이는 거 잘 생각해야 됨
스칼라 값: 1개의 값
- 프로덕트 선정
-- [ 집계 함수 ] --
-- 그룹 바이 --
select name , count(name), sum(quantity) from sample51 s
group by name order by sum(quantity) desc ;
-- 안됨. 집계하는 열이 2개인데 어쩌고 해서 안되는 거임. 집계함수 원리 알아보삼.
select name , count(name), sum(quantity) from sample51 s ;
select * from sample51 s
select * from track t;
desc track
-- 후덜덜이 실습 타임 --
Q1. track 테이블을 사용하여 다음 정보를 조회하는 쿼리를 작성하세요:
• 각 아티스트의 ID (Composer 컬럼 사용)
각 아티스트가 작곡한 트랙의 수
각 아티스트의 트랙들의 총 재생 시간 (분 단위로 변환)
각 아티스트의 트랙들의 총 가격트랙 수가 5개 이상이고,
총 재생 시간이 30분을 초과하는 아티스트만 조회
결과를 트랙 수가 많은 순서대로 정렬
-- X. where이 제일 먼저 되는데 집계 안된 상황에서 하라니까 안되었던 거임... 나~참내~ 그럼 셀렉트에서 함수 넣고 뽑으면 웨얼에서 못하나? 웨얼에서 해야 하나? 그럼 셀렉트에선 왜 함?
-- 총 재생시간이 30분을 초과하는지 아닌지를 웨얼에서는 알 수 없음 셀렉트에서 구하니까. 웨얼에서 집계를 못쓰나 웨얼에서 계산하는 걸로 안쳐주네 흠...
select
case
when Composer is null then '미상'
else Composer
end as "작곡가 이름",
count(Name) as "작곡한 노래 수", sum(Milliseconds) / 60000 as "총 재생시간(분)", sum(UnitPrice)
from track t
where count(Name) >= 5 and sum(Milliseconds) / 60000 > 30
group by Composer
order by count(Name);
-- o case로 null 생략하게 못하나
select
case
when Composer is null then '누가 지은지 모름 ㅅㄱ'
else Composer
end as "작곡가 이름",
count(Name) as "작곡한 노래 수", round(sum(Milliseconds) / 60000 as "총 재생시간(분)", sum(UnitPrice) as "이 사람 거 다 사려면 털리는 재산 ㄷㄷ"
from track t
group by Composer having count(Name) >= 5 and sum(Milliseconds) / 60000 > 30
order by count(Name) desc;
-- O 강사님 풀이. 오더바이에서는 비로소 셀렉트에서 붙인 애칭을 넣을 수 있다.
select Composer , count(*) as trackcount,
count(Name) as "작곡한 노래 수", sum(Milliseconds) / 60000 as "총 재생시간(분)", sum(UnitPrice) as "이 사람 거 다 사려면 털리는 재산 ㄷㄷ"
from track t
where Composer is not null
group by Composer having count(Name) >= 5 and sum(Milliseconds) / 60000 > 30
order by trackcount desc;
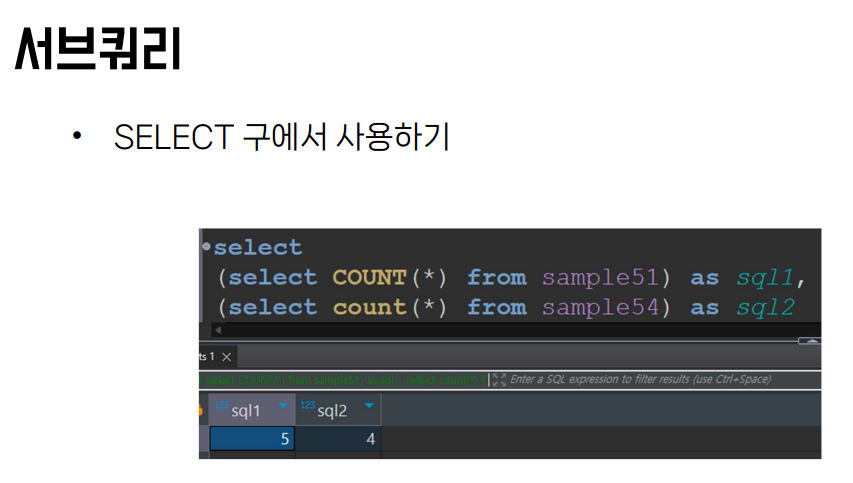
서브 쿼리
쿼리 안에 셀렉트를 또 넣는 걸 말합니다. 주로 1개까지만 넣습니다(2개 이상 중첩해 넣으면 성능 염려 ㄷ)
왜 쓰냐면 AVG 등의 집계 함수를 웨얼에선 쓸 수 없고,
그렇다고 셀렉트에서 쓴 걸 웨얼에선 활용 못시키고 등등의 이유가 있기 때문.
SELECT ProductName, Price FROM Products WHERE Price > (SELECT AVG(Price) FROM Products);
어디 테이블 안에 종속되어 있다 말하기 어려우니까, 이럴 때는 from 생략 가능.
성능에 영향을 줄 수 있어서 과도한 사용은 ㄴㄴ.

사실 예시의 경우에는 테이블이 같으니까 그냥 a = max(a) 하면 되긴 함.
테이블과 열이 다르다고 생각해주셈 그럴 땐 서브쿼리를 쓸 수 밖에 없으니까.
아님 join 쓰며는 서브쿼리 급유용해짐.
예시 구문은 set에서도 쓸 수 있다고 보여주기 위해서 단순하게 급조한 것.
from, where, select 에서 다 쓸 수 있음.

쿼리 안에 들어간 셀렉트 구문이 바로 서브쿼리임. 다른 말로는 중첩구조, 내포구조.
중첩구조 4~5단계도 가능함. 서브쿼리 안에 서브쿼리 넣고...
근데 보통 3단계까지도 안갈 거임 성능상으로도 안좋고.

프랑구에서 집계 쓸 수 있으면... 프랑에서 집계 해놓고...
어 위에 실습문제도 프랑 서브쿼리로 풀 수 있는 거 아녀?!
서브쿼리를 웨얼 구에 쓰는 이유가
웨얼 구에서는 집계 못씀
where Milliseconds > avg(Milliseconds)
이걸 못한단 말임.
/
그렇다고 셀렉트에 넣기에는 웨얼부터 다루니까 오류가 남. 웨얼에서 어떤 조건들을 찾아서 출력하려고 보니까? 막
where (select avg(t2.Milliseconds) < t2.Milliseconds from track t2)
이게 안됐던 이유
셀렉트 문 안에서는 비교연산자 못넣음 (?)
여기서 넣어봤자 트루다 아니다만 나올 거임 . 웨얼 안에 들어간 서브쿼리니까...
where Milliseconds > (select avg(Milliseconds) from track)
이게 맞음.
select Name , Milliseconds , (select avg(Milliseconds) > t.Milliseconds from track t2 ) as "평균과 차이"
from track t ;
어쩐지 이거는 0이냐 1이냐로 나오더라고

SELECT
Composer,
count(*) as trackcount,
sum(Milliseconds) / 60000 as totalDuration,
sum(UnitPrice)
from Track t
where Composer is not null
group by Composer
HAVING count(*) >= 5 AND sum(Milliseconds) / 60000 > 30
order by trackcount desc, totalDuration desc;
-- Q1. 평군 곡 길이보다 긴곡들의 이름과 길이를 조회하세요. (where)
SELECT Name , Milliseconds
FROM Track t
where Milliseconds > ( SELECT avg(Milliseconds) from Track t);
-- Q2.각 장르별 평균 곡 길이 (초단위)를 조회하세요 (FROM)
SELECT *
from (SELECT GenreId , avg(Milliseconds) / 1000 as average
from Track t
group by GenreId ) tabgd;
-- Q3. 모든 트랙의 이름, 길이(밀리초), 그리고 평균 트랙길이와의 차이를 조회하세요 (select)
SELECT
name, Milliseconds,
(SELECT avg(Milliseconds) from Track t) - Milliseconds as difference
from Track t ;
ㄹㄹ
스칼라값: 하나의 값만 뽑는 것
COUNT SUM 등 딱 하나의 값만 나오게 하는 거 ㅇㅇ
오후 강의
| 소제목
요약
in / exists
- 프로덕트 선정

이 집합 안에 같은 게 있는지 없는지를 exist를

in은 많이 쓸 것 같음. case에도 쓸 수 있나? 가능 조건식으로.
그럼 들어가있으면 뭐로 뜨게, 아님 null을 다른 거로 뜨게 할 수 있겠군. 근데 그냥 null의 표시값을 옵션에서 바꾸는 게 나을듯 함.
in이 조금 더 집합도 비교할 수 있는 녀석
열이 1개밖에 없는 서브쿼리가 스칼라. 셀렉트열에 들어가는 서브쿼리는 스칼라일 수밖에 .. (? 팩쳌)
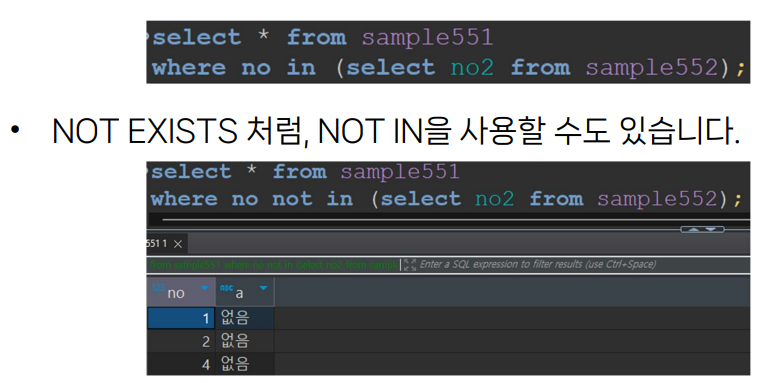
-- IN 직접 해보기
SELECT
CustomerId , count(CustomerId), sum(Total), BillingCountry
from Invoice i
where CustomerId IN (SELECT CustomerId from Invoice WHERE BillingCountry = "USA")
group by CustomerId,BillingCountry ;
SELECT * from Invoice WHERE BillingCountry = "USA"
- 프로덕트 선정
집합
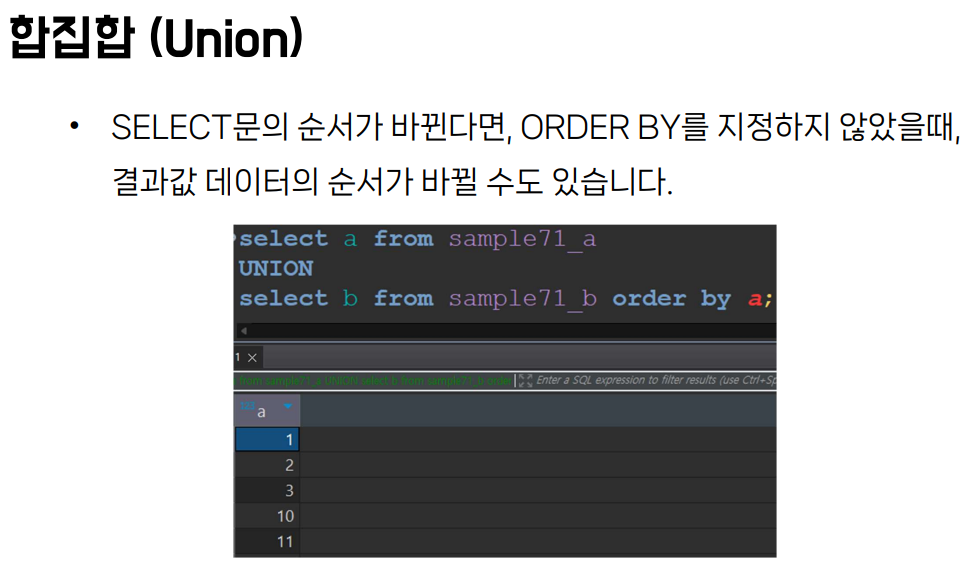
- union 합집합
- 셀렉트문은 모두 열을 하나만 가지고 올 수 있게 명시해놨다
- 유니온을 사용하실 때 열의 갯수를 통합시키는 게 중요하다.
- 기준이 되는 건 첫번째로 나온 열이다.
- order by를 쓸 수 있어요. 이걸 쓰지 않으면 순서가 와리가리 하게 바뀔 수 있어요.
- 마지막 셀렉트 열에만 지정을 해줘요.
- 그치만 첫번째로 나온 열로만 정렬을 해줘야 돼요.
- 마지막 셀렉트열에서 끌어온 테이블에 열이 없어도 (b 테이블에 a란 열이 없어도) 정렬을 시킬 수 있어요.
- 근데 헷갈릴 수 있으니, 걍 둘다에 별명을 붙이소 - 분명 열이 다른데도 같은 별명을 가져도 되는 이유는 어차피 합쳐지기 때문.
- 어? 어차피 합칠 거면 b(두번째로 나온 합칠 대상이 되는 열)로 해도 되는 거 아니에요? 안돼요 왜냐면
- 내부 처리 순서 때문. 합치는 걸 실행해서... 첫번째 열 이름을 기준으로 합쳐뒀는데... b로 정렬하라니 뭔 소리야! 가 되는 거임. a로 정렬하라고 하거나 별명으로 정렬하라 하면 ㅇㅋㅇㅋ
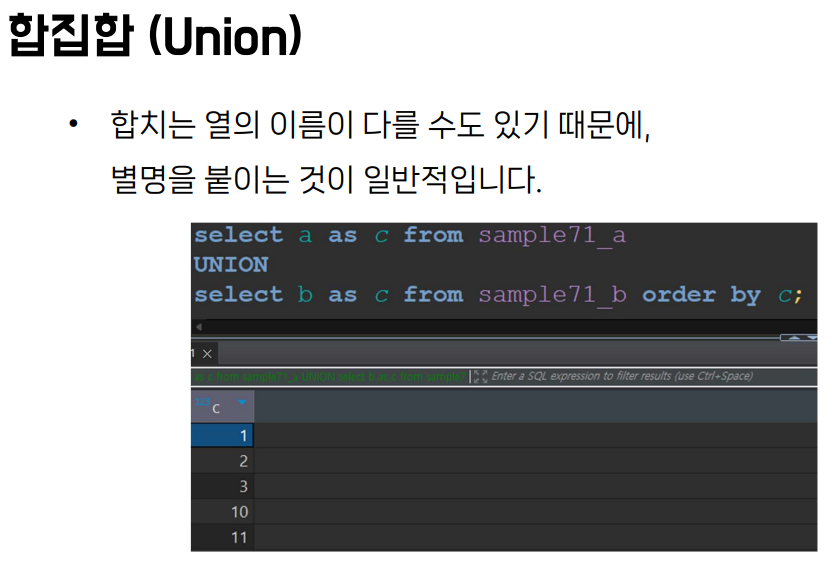
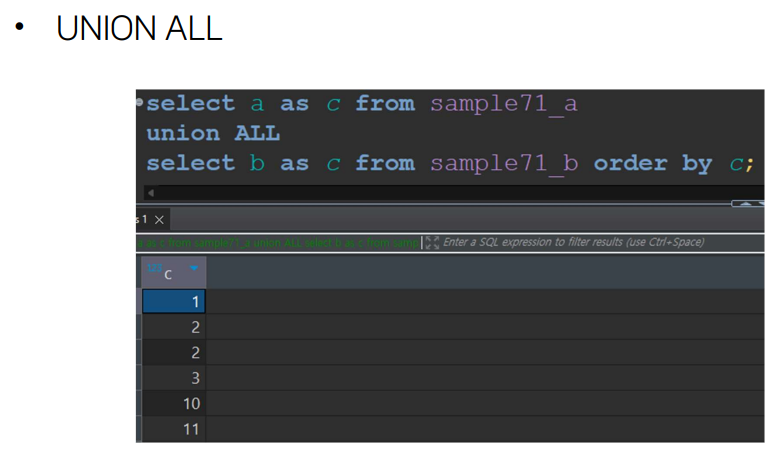
중복 나오게 하고 싶을 때는 union all
join 테이블 결합. 조인

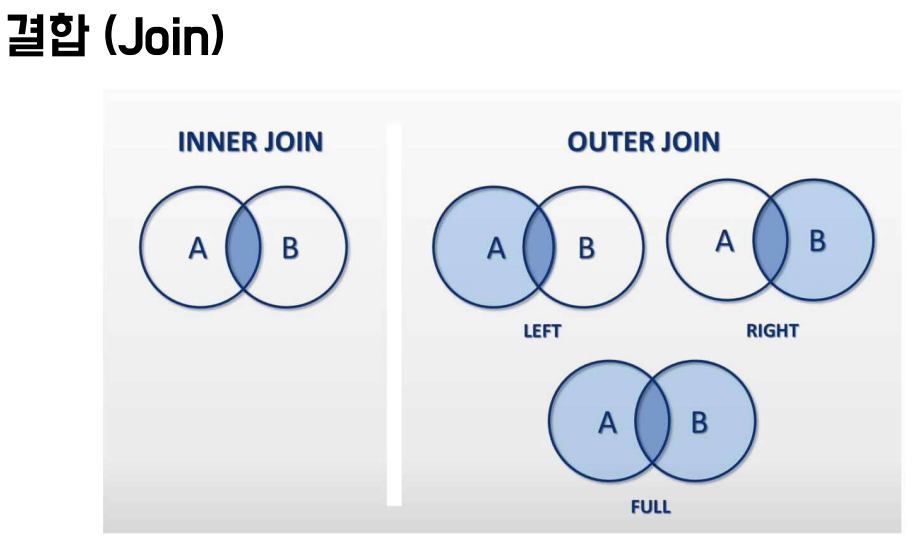
SELECT * FROM 테이블명1 INNER JOIN 테이블명2 ON 결합조건
인보이스라인
주문서에서 뭘 샀고 얼마나 가격은 어케 됐는지.
인보이스가 기준인데
어떤 고객이 어떤 트랙을 샀고 그 트랙 앨범 이름 가져오고
- 프로덕트 선정
Inner Join 예시 쿼리문
SELECT
c.LastName,
c.FirstName,
t.Name AS TrackName,
a.Title AS AlbumTitle
FROM
Customer c
INNER JOIN Invoice i ON c.CustomerId = i.CustomerId
INNER JOIN InvoiceLine il ON i.InvoiceId = il.InvoiceId
INNER JOIN Track t ON il.TrackId = t.TrackId
INNER JOIN Album a ON t.AlbumId = a.AlbumId
ORDER BY
c.LastName, c.FirstName;
- 프로덕트 선정
<내가 입력한 풀이들>
-- 1
select A.Title, A2.Name
from album a
inner join artist a2
on A.ArtistId = A2.ArtistId ;
-- 2
select g.Name, count(TrackId) as "곡 수", round(sum(Milliseconds) / 60000) "총 재생 시간(분)"
from track t inner join genre g
on t.GenreId = g.GenreId
group by g.Name ;
-- 3
select concat(c.FirstName, " ", c.LastName) as name , sum(I.Total) as "총 구매횟수"
from customer c
inner join invoice i
on C.CustomerId = I.CustomerId
group by name
order by sum(I.Total) desc ;
- 강사님
inner join 직접해보기! Q1, Q2 해답 올려드립니다~
SELECT
al.Title AS AlbumTitle,
ar.Name AS ArtistName
FROM Album al
INNER JOIN Artist ar ON al.ArtistId = ar.ArtistId
ORDER BY
ar.Name, al.Title;
SELECT
g.Name AS GenreName,
COUNT(t.TrackId) AS TrackCount,
SUM(t.Milliseconds) AS TotalDuration
FROM Genre g
INNER JOIN Track t ON g.GenreId = t.GenreId
GROUP BY
g.GenreId, g.Name
ORDER BY
TrackCount DESC;
- 프로덕트 선정
- 프로덕트 선정
- 프로덕트 선정
- 프로덕트 선정
여담
[회고]
하 나 할 거 많은데
오늘ㅇㄴ 하루종일 졸리고 피곤하고 컨디션 맛이 갔다.
그래서 남아서 자습도 못하겟고 기술블로그도 이 모냥이다.
이럴 땐 집에 가서 쉬어야 하는데
완전 레전드 오랜만에 일정 없으면서 집에 바로 가는 날이 되는데
문제는! 오늘 독서모임이 있다는 것.
피곤한데 어떠카지
밤샌 것도 아니고 컨디션 왜 이러지 며칠전부터 쌓인건지 아님 나도 모르게 어디가 아픈건지
오래된 거 먹었던 탓인지??
집에 가서 쉬고 싶다...
체력 회복되면 수정해야 할텐데 참...
#청년취업사관학교 #데이터분석가 #데이터분석가부트캠프 #DA교육 #데이터분석교육 #실무프로젝트 #실무경험 #취업포트폴리오 #포트폴리오 #취업연계교육 #코멘토 #모비니티
'새싹 데이터 분석 교육 (24.05.13~24.08.16) > TIL' 카테고리의 다른 글
| [성동2기 전Z전능 데이터 분석가] 0711 (1) | 2024.07.11 |
|---|---|
| [성동2기 전Z전능 데이터 분석가] 0710 (0) | 2024.07.10 |
| [성동2기 전Z전능 데이터 분석가] 0708 (미완) (1) | 2024.07.08 |
| [성동2기 전Z전능 데이터 분석가] 0705 (미완) (0) | 2024.07.08 |
| [성동2기 전Z전능 데이터 분석가] 0704 (미완) (0) | 2024.07.08 |



